Learn Authentication The Hard Way: Part Three
This is the final installment of a three part series in which we dive into modern application authentication solutions - the hard way.
Part Two: The Hard Way, Continued
Part Three: The Hard Way: Return Of The Specification
The Hard Way: Return Of The Specification
We are continuing our quest to implement a client that will perform the OpenID Connect Authorization Code Flow. It is one of the two flows we need to know to cover most of our application authentication needs.
Why would we want to do this? Make sure to read Part One for the motivation behind this endeavour.
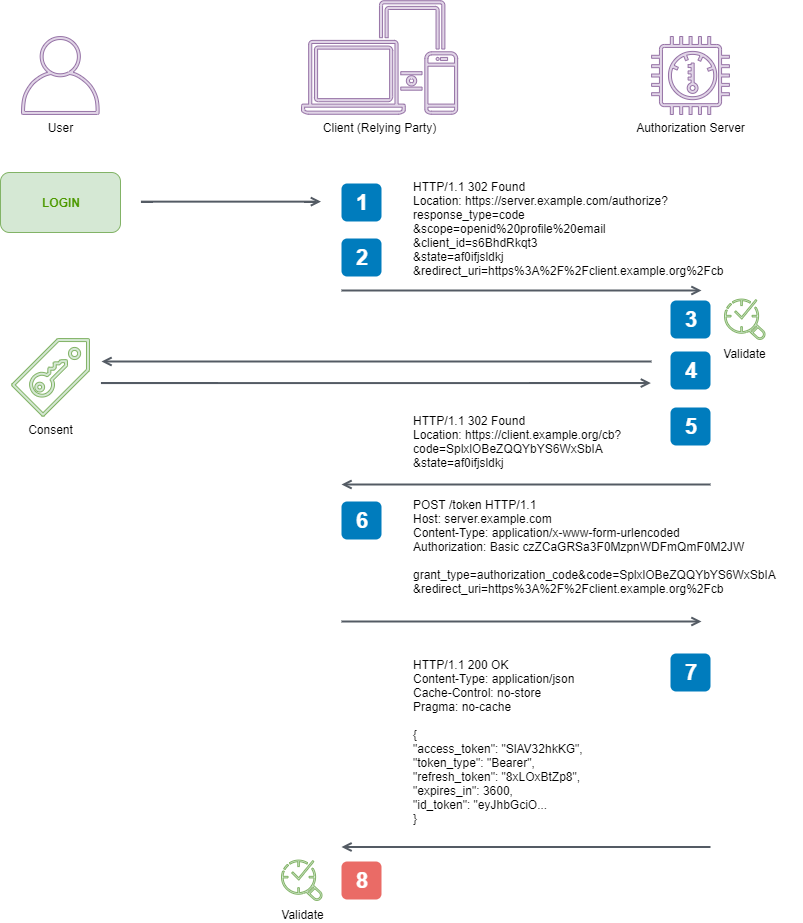
Here are the steps taken from the specification that we are going to facilitate to perform an end-to-end Authorization Code Flow:
1. Client prepares an Authentication Request containing the desired
request parameters.
2. Client sends the request to the Authorization Server.
3. Authorization Server Authenticates the End-User.
4. Authorization Server obtains End-User Consent/Authorization.
5. Authorization Server sends the End-User back to the Client with an
Authorization Code.
6. Client requests a response using the Authorization Code at the Token
Endpoint.
7. Client receives a response that contains an ID Token and Access
Token in the response body.
8. Client validates the ID token and retrieves the End-User's Subject
Identifier.
In Part Two we powered through implementing steps 2 through 7, and discovered that specs are indeed written by engineers. In this final post we will breeze through the eighth and final step.
8. Client validates the ID token and retrieves the End-User’s Subject Identifier
We are now on the home stretch - all we need to do is to validate the payload we have received, and then we will have successfully completed the Authorization Code Flow!
3.1.3.5. Token Response Validation
...
Follow the validation rules in RFC 6749, especially those in
Sections 5.1 and 10.12.
...
So this is an interesting piece of advice. The first part of the statement is a cover-all for the OAuth 2.0 spec which isn’t particularly useful. If we begin at 4.1.4. Access Token Response in RFC 6479, we can see it is mostly ensuring we only accept specified values from our Authorization Server, and ignore anything else - this covers Section 5.1 as well.
The interesting part comes in advising us to follow Section 10.12 - which we covered earlier. It was our CSRF protection mechanism for the initial redirection and callback, ensuring unwanted types couldn’t randomly call our redirect endpoint. Why would we need to implement CSRF protection on a single HTTPS call to the token endpoint? Well we don’t need to - it doesn’t make any sense to, as the communication isn’t succeptible to CSRF. Published specifications can also have bugs.
Our deserialization process will ensure 3.1.3.5 is adhered to, so let’s move on to validating our tokens. I’ll only address validation items that apply to us within 3.1.3.7. ID Token Validation - any numbered items I do not mention address less common, more sophisticated scenarios, beyond the scope of this post.
3.1.3.7. ID Token Validation
Clients MUST validate the ID Token in the Token Response in the
following manner:
...
2. The Issuer Identifier for the OpenID Provider (which is typically
obtained during Discovery) MUST exactly match the value of the
iss (issuer) Claim.
...
🚨 New Term Alert 🚨 What is Discovery? Once again, let’s Ctrl+f our way to success. Way up in 1. Introduction in the Open ID spec, the following information is offered:
This specification assumes that the Relying Party has already obtained configuration information about the OpenID Provider, including its Authorization Endpoint and Token Endpoint locations. This information is normally obtained via Discovery, as described in OpenID Connect Discovery 1.0.
We have been working through the OpenID Core specification, which details the main functionality OpenID Connect layers on top of the OAuth 2.0 spec. However OpenID also defines a number of other specifications dealing with ancillary concerns - one of them being Discovery.
4. Obtaining OpenID Provider Configuration Information within the Discovery specification tells us how to obtain provider information - by issuing a GET request to /.well-known/openid-configuration - commonly referred to as the well known configuration endpoint.
The spec provides us with a schema for the expected response. At this point we are going to start dealing with lots of json formatted data. To make this job easier, I’ll be using QuickType, an awesome tool for scaffolding C# classes from json schemas, which comes with the added benefit of providing both neat type inference and serialization helpers so that you can just ‘plug and play’ what it supplies.
public class OpenIDConfiguration
{
[JsonProperty("issuer")]
public string Issuer { get; set; }
[JsonProperty("jwks_uri")]
public string JwksUri { get; set; }
...
}We now have our Authorization Server’s OpenID Configuration information, so we can now begin validating the ID Token we recieved in the response from the /token endpoint request.
3.1.3.7. ID Token Validation
...
2. The Issuer Identifier for the OpenID Provider (which is typically
obtained during Discovery) MUST exactly match the value of the iss
(issuer) Claim.
3. The Client MUST validate that the aud (audience) Claim contains
its client_id value registered at the Issuer identified by the iss
(issuer) Claim as an audience.
...
const string introspectionEndpoint = "http://localhost:8080/.well-known/openid-configuration";
var configurationJson = await new HttpClient().GetStringAsync(introspectionEndpoint);
var configuration =
JsonConvert.DeserializeObject<OpenIDConfiguration>(configurationJson, Converter.Settings);
// 3.1.3.7. ID Token Validation
body.Iss.MustEqual(configuration.Issuer, "Invalid issuer encountered");
body.Aud.MustEqual("client", "Invalid audience encountered");Just when you thought we were out of the woods with this implementation, we come across this statement:
3.1.3.7. ID Token Validation
...
6. If the ID Token is received via direct communication between the
Client and the Token Endpoint (which it is in this flow), the TLS
server validation MAY be used to validate the issuer in place of
checking the token signature. The Client MUST validate the signature
of all other ID Tokens according to JWS using the algorithm
specified in the JWT alg Header Parameter. The Client MUST use the
keys provided by the Issuer.
...
Although our scenario has us communicating directly with the Token Endpoint (and we should be using HTTPS), understanding how tokens and their signatures function is core to our understanding of the security solution, as they are an integral part of it. If we skip this step, we have a glaring gap in our knowledge of the solution. So, let’s dive in!
🚨 New Spec(s) Alert 🚨 The JWS specification describes the mechanism used to ensure JWTs are made tamper-proof and validatable. The JWS specification relies on the JWA specification to define what cryptographic mechanisms are available to generate signatures. The JWS specification is strongly linked to the JWT specification, which refers back to the JWS specification when describing how to validate JWTs.

Come back! We aren’t going to have to read three new specs end-to-end, although this is the danger of diving into specifications - sometimes you don’t know where the rabbit holes will end. In our case we are only concerned with validating the signature on our ID Token, so let’s try and limit our exploration of the token specifications to this topic.
Starting with 7.2. Validating a JWT, there are some basic formatting and encoding checks to perform, but the interesting part starts with:
6. Determine whether the JWT is a JWS or a JWE using any of the
methods described in Section 9 of [JWE].
7. Depending upon whether the JWT is a JWS or JWE, there are two
cases:
* If the JWT is a JWS, follow the steps specified in [JWS] for
validating a JWS. Let the Message be the result of base64url
decoding the JWS Payload.
I find their usage of the labels “JWS” and “JWE” to infer a type of token, rather than the cryptographic mechanism used to secure it, to be very confusing. The short of it is JWS == signed token, JWE == encrypted token. Both are JWTs.
If we jump across to Section 9 of the JWE specification as directed, it gives us a straightforward way to determine which type we might be dealing with - JWS uses a three segment token delimited by ., and JWE uses a five segment token delimited by .. If you want a more sophisticated way, you can examine the value of the alg header parameter - if it is one of the values defined in Section 3 of the JWA specification, it is an algorithm for digital signatures or MAC, and the token is therefore a JWS JWT.
Which algorithm is used to sign the token will depend on what our Client’s registration with the Authorization Server. OpenID Connect specifies a default of RS256, which refers to the RSASSA-PKCS1-v1_5 using SHA-256 algorithm.
RS256 utilises a Digital Signature-based approach, which involves using an asymmetric key pair (public/private keys) along with a strong hashing algorithm, composing the JWS Signing Input out of the JWT contents, computing the hash over the input, encrypting the has using the private key from the key pair, and appending the hash to the JWT. If you really want to crack open another spec and dive into the guts of how this works, you can read RSA Cryptography - 8.2. RSASSA-PKCS1-v1_5.
Note that this digital signature is more sophisticated than a simple MAC based approach - the use of an asymmetric key pair makes stronger guarantees of a signatures authenticity, where the MAC approach simply relies on a single shared secret being available to all parties involved.
The JWS specification - 5.2. Message Signature or MAC Validation tells us what we need to do to validate our JWS token:
Validate the JWS Signature against the JWS Signing Input
ASCII(BASE64URL(UTF8(JWS Protected Header)) || '.' ||
BASE64URL(JWS Payload)) in the manner defined for the algorithm
being used, which MUST be accurately represented by the value of
the "alg" (algorithm) Header Parameter, which MUST be present.
Clear as mud right - in the manner defined for the algorithm being used is a super useful instruction!
This is instruction is going to cause us to pore over the JWS and JWE spec to try and find more explicit instructions, and likely start googling like mad for implementations in our language of choice.
Our signing algorithm RS256 uses an asymmetric key-pair to do its job, and we need to retrieve the public key of this key pair so that we can validate the signature generated by the algorithm.
The JWS specification specifies the location where keys can be retrieved from, and references YET ANOTHER specification for how keys are represented within JWTs - the JWKs specification. Appendix B provides a neat example of how JWK represents a RSA public key.
Piecing all of this together, what we need to accomplish is:
- Retrieve our RSA public key components in JWK format via the endpoint defined in our Authorization Server’s well known configuration
- Follow the JWS specification - Section 5.2 to construct the JWS Signing Input in the format
ASCII(BASE64URL(UTF8(JWS Protected Header)) || '.' || BASE64URL(JWS Payload)) - Compute the hash of the JWS Signing Input with
SHA256. - Verify the computed hash against the signature we recieved in the third segment of our ID token using our RSA public key
- Profit! If the verification passes, we can be comfortable that the token we have recieved could only have been constructed by our Authorization Server, and that it has not been tampered with in transit.
var rawHeader = DecodeSegment(idToken, TokenSegments.Header);
var rawBody = DecodeSegment(idToken, TokenSegments.Body);
// IETF JWS Draft
// 5.2. Message Signature or MAC Validation
// https://tools.ietf.org/html/draft-ietf-jose-json-web-signature-41#section-5.2
var keysetJson = await new HttpClient().GetStringAsync(configuration.JwksUri);
var keyset = JsonConvert.DeserializeObject<KeySet>(keysetJson, Converter.Settings);
var rsa = RSA.Create();
rsa.ImportParameters(new RSAParameters
{
Exponent = WebEncoders.Base64UrlDecode(keyset.Keys[0].E),
Modulus = WebEncoders.Base64UrlDecode(keyset.Keys[0].N),
});
var canonicalPayload =
Encoding.ASCII.GetBytes(
$"{WebEncoders.Base64UrlEncode(Encoding.UTF8.GetBytes(rawHeader))}." +
$"{WebEncoders.Base64UrlEncode(Encoding.UTF8.GetBytes(rawBody))}");
var hash = SHA256.Create().ComputeHash(canonicalPayload);
// https://tools.ietf.org/html/rfc3447#section-8.2.1
var result = rsa.VerifyHash(hash, rawSignature, HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
if (!result) throw new InvalidOperationException("The supplied signature does not match the calculated signature");
...
private enum TokenSegments
{
Header = 0,
Body,
Signature
}
private static string DecodeSegment(string token, TokenSegments desiredSegment)
{
var tokenSegments = token.Split(".");
if (tokenSegments.Length != 3) throw new InvalidOperationException("Unexpected token format encountered");
var target = tokenSegments[(int)desiredSegment];
// NOTE: WebEncoders.Base64UrlDecode deals with IDSrv truncating padding from encoded tokens
var unencodedBytes = WebEncoders.Base64UrlDecode(target);
var segment = Encoding.UTF8.GetString(unencodedBytes);
return segment;
}And now, we understand JW(T/S/E/K) tokens.

With signature verification out of the way, the last part of the ID token we need to verify is:
3.1.3.7. ID Token Validation
...
9. The current time MUST be before the time represented by the exp
Claim.
This is much easier to do - although we do need to understand what format the time is expressed in, and that is an implementation detail left up to the implementer of the Authorization Server. Identity Server uses seconds from Unix epoch.
...
if (DateTimeOffset.FromUnixTimeSeconds(body.Exp) <= DateTimeOffset.UtcNow)
{
throw new InvalidOperationException("Token has expired");
}
...The final specified behaviour for the Authorization Code Flow is:
3.1.3.8. Access Token Validation
When using the Authorization Code Flow, if the ID Token contains an
at_hash Claim, the Client MAY use it to validate the Access Token in
the same manner as for the Implicit Flow, as defined in Section
3.2.2.9, but using the ID Token and Access Token returned from the
Token Endpoint.
Although it isn’t a MUST, anything regarding how we validate the payloads delivered by this solution will boost our understanding of it. If we visit 3.2.2.9. Access Token Validation as directed, our instructions are to:
Hash the octets of the ASCII representation of the access_token...
Take the left-most half of the hash and base64url encode it.
The value of at_hash in the ID Token MUST match the value produced in
the previous step.
Did it just give a succinct and explicit explanation of how to implement one of its behaviours?

// 3.1.3.8. Access Token Validation
// 3.2.2.9. Access Token Validation
// https://openid.net/specs/openid-connect-core-1_0.html#ImplicitTokenValidation
private static TokenValidationResult ValidateAccessToken(string idToken, string accessToken)
{
var rawBody = DecodeSegment(idToken, TokenSegments.Body);
var body = JsonConvert.DeserializeObject<JwtBody>(rawBody, Converter.Settings);
var octets = Encoding.ASCII.GetBytes(accessToken);
var hash = SHA256.Create().ComputeHash(octets);
var encoded = WebEncoders.Base64UrlEncode(hash[..(hash.Length / 2)]);
if (encoded.Equals(body.AtHash) == false) throw new InvalidOperationException("The supplied signature does not match the calculated signature");
return new TokenValidationResult { Succeeded = true };
}And with that, we are DONE.
Disclaimer
What we have built here is NOT a production ready solution.
OAuth 2.0 Security Best Current Practice provides guidance beyond the original RFC 6479 and OpenID Connect specification that MUST be considered and implemented as appropriate in any production-ready solution.
Auth0 have written a great article from a client point of view on considerations that should be given when designing your client’s security implementation.
Looking to the future, Aaron Parecki has written a fantastic post foreshadowing OAuth 2.1 and how it may simplify the web of entangled, aging RFC documents we are currently faced with when making decisions about how best to implement or adopt modern authentication solutions.
Postface
All of the code referenced in this article is available on GitHub.
My take-aways from this exercise have been:
- Security specifications stand on the shoulders of giants - the layers of specification involved in these solutions is astounding, and the depth of thought and debate involved in producing them impressive.
- You shouldn’t roll your own. Really. There is just no way you would have time to digest all of the information required if you wanted to make a conformant solution for any non-trivial scenario.
- Specifications aren’t that scary or difficult to consume - until you get to the Crypto specs.
- Having a go at implementing a specification (or part thereof) WILL help embed your knowledge of it. It is a fantastic forcing function.

Charlie attempts to link together the various specifications needed to roll his own auth